Line.content CAN be null. It is in fact what is use to determine if we are at the end of the file.Okay. It looks like Token.content can never be null, as Token() always initializes it with either ";" or the result of some substring call. But do we have that same guarantee within Line.content (which is used to populate Token.content)? It doesn't look like it.
Either way, I don't trust myself to catch everything tonight. Sorry.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Feature ASH language server features
- Thread starter fredg1
- Start date
@heeheehee I found and fixed a bug in the previous patch. I was making a standalone token out of the braces of string templates (`something{ 1 + 1 }something else`).
Turns out, if spaces were following the closing brace, they would get erased.
(I was doing this because I was giving them both (the braces) a colour distinct from the string's colour, in the language server. I'll have to think of something else for that)
This patch has the bug fixed.
Turns out, if spaces were following the closing brace, they would get erased.
(I was doing this because I was giving them both (the braces) a colour distinct from the string's colour, in the language server. I'll have to think of something else for that)
This patch has the bug fixed.
Attachments
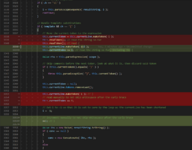
These seem like weird lines to have next to each other:
Once again, I get that you're doing this as part of developing a language server (for syntax highlighting, from your comment?), but I would really appreciate if you added some tests to codify the exact behavior you're trying to ensure stays the same. Even something like:
assertThat("int i = 5; print(`this prints {i} in the middle of some text`);", hasOutput("this prints 5 in the middle of some text");
(as a simpler, table-based set of behavioral tests for ASH; I'd be able to run and commit that separately from this actual change. I appreciate that you're putting in this work, and I get that the last thing programmers want to be told is "write more tests" especially if there are none in the existing codebase. But I simply don't feel comfortable committing an untested change this large without at least another dev or two willing to also vouch for it, since I know I miss things in code review all the time.)
Java:
// Set i to -1 so that it is set to zero by the loop as the currentLine has been shortened
i = -1;
+ // increment manually to not skip whitespace after the curly brace
+ ++i; // }
+Once again, I get that you're doing this as part of developing a language server (for syntax highlighting, from your comment?), but I would really appreciate if you added some tests to codify the exact behavior you're trying to ensure stays the same. Even something like:
assertThat("int i = 5; print(`this prints {i} in the middle of some text`);", hasOutput("this prints 5 in the middle of some text");
(as a simpler, table-based set of behavioral tests for ASH; I'd be able to run and commit that separately from this actual change. I appreciate that you're putting in this work, and I get that the last thing programmers want to be told is "write more tests" especially if there are none in the existing codebase. But I simply don't feel comfortable committing an untested change this large without at least another dev or two willing to also vouch for it, since I know I miss things in code review all the time.)
I am, actually, completely new to this side of programming (writing "tests"), have no (well, "very little") idea how to do it, and would very much appreciate if you could help me understand how to make those.[...] and I get that the last thing programmers want to be told is "write more tests" especially if there are none in the existing codebase. [...]
I wouldn't mind adding/making them then.
") (partly because I already care about making sure the behaviour is the same, and what I'm currently doing is just to run scripts that I have and observing if the outcome is the same as before, so actual tests would help)
(partly because I already care about making sure the behaviour is the same, and what I'm currently doing is just to run scripts that I have and observing if the outcome is the same as before, so actual tests would help)(btw, thanks for taking your time so far)
r20816 adds test/net/sourceforge/kolmafia/textui/ParserTest.java, which I hope is fairly self-explanatory if you want to expand it with additional test cases. It's not a unit test, but rather a functional test that treats the entire Parser as a black box. Script goes in, error comes out (or possibly no error).
To run it (and the rest of our test suite), run `ant test` from the repo root directory, similar to how you build Mafia in the first place.
Another similar test, as present in CustomScriptTest, is "what does this script yield as output?" For that, I had set up a fake KoLmafia root under test/root, where you can add .ash and .txt (and possibly .js) scripts to test/root/scripts, run the tests as before, and validate the expected output against a golden file in test/root/expected/.
One aspirational target / metric with testing is something called "code coverage", which measures the lines of code that are exercised in tests. (There's also a notion of branch coverage, which checks your coverage of if-statements and the like.) We've talked about integrating with tools like OpenClover, but we haven't gotten around to it.
To run it (and the rest of our test suite), run `ant test` from the repo root directory, similar to how you build Mafia in the first place.
Another similar test, as present in CustomScriptTest, is "what does this script yield as output?" For that, I had set up a fake KoLmafia root under test/root, where you can add .ash and .txt (and possibly .js) scripts to test/root/scripts, run the tests as before, and validate the expected output against a golden file in test/root/expected/.
One aspirational target / metric with testing is something called "code coverage", which measures the lines of code that are exercised in tests. (There's also a notion of branch coverage, which checks your coverage of if-statements and the like.) We've talked about integrating with tools like OpenClover, but we haven't gotten around to it.
@heeheehee I made a test for string templates. While doing it, I noticed that I, yet again, did a mistake (this sure isn't helping my credibility...) in the previous patch - I wasn't supposed to touch how the *opening* curly brace was read (using readToken() rather than manually incrementing currentIndex)
Attached are the (hopefully final...) patch, as well as the before-after of what I did in it (notice that I re-added the start of line 3338, and restored the use of readToken() on line 3339)
(I'll add the test on the next post)
Attached are the (hopefully final...) patch, as well as the before-after of what I did in it (notice that I re-added the start of line 3338, and restored the use of readToken() on line 3339)
(I'll add the test on the next post)
Attachments
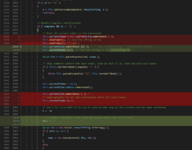
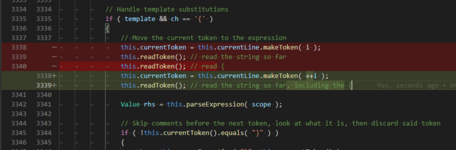
On the contrary: this is why we write tests.this sure isn't helping my credibility...)
r20817
(I don't mind committing multiple small tests at once as long as they seem reasonable.)
Here's a few more tests.
These tests touch the various parts that received a somewhat important change in my "Tokens" patch: strings, typed constants and plural constants.
(It's worth noting that I didn't touch directives, even though they did receive an important change. This is because they are preeeetty hard to test...)
These tests touch the various parts that received a somewhat important change in my "Tokens" patch: strings, typed constants and plural constants.
(It's worth noting that I didn't touch directives, even though they did receive an important change. This is because they are preeeetty hard to test...)
Attachments
These seemed unobjectionable, thanks! r20819.
I'm surprised by a couple of these tests, but they make sense.
Non-successive characters and multiline in particular -- I knew you could split a name across multiple lines, just didn't realize you could do it mid-word.
I spent yesterday working on integrating OpenClover, which I submitted this morning. (There's another short story describing briefly how to invoke it, etc. I suppose I didn't say anything about how to read the resulting report, but in short, you can drill down into individual source files to see which lines are exercised by existing tests -- green = covered, red = uncovered. Now I'm wondering if OpenClover has a colorblind-friendly mode...)
Taking advantage of that, I see some untested behavior in parseString:
- unterminated plural constant (e.g. `$booleans[`)
- other escaped sequences (end-of-string, e.g. "\"", "\r", "\t", "\,", "\xABCD", "\uABCD", "\777") as well as malformed variants (invalid hex sequences, invalid octal)
- unterminated template substitutions
- comments
- nested brackets within a typed constant, e.g. $item[[glitch season reward name]])
(Just as some food for thought, to get you started down the rabbit hole that is coverage.)
Now, obviously I don't expect you to get Parser.java up to 100% absolute coverage, so use your judgment for which cases you're most worried about / which cases your parsing changes are most likely to have impacted.
(There's a notion of incremental code coverage as well, which is filtered down to the lines that you've added/modified. I'd like that to be no less than 80%, but preferably 90-100%. I don't see a great way of measuring that in OpenClover, though.)
I'm surprised by a couple of these tests, but they make sense.
Non-successive characters and multiline in particular -- I knew you could split a name across multiple lines, just didn't realize you could do it mid-word.
I spent yesterday working on integrating OpenClover, which I submitted this morning. (There's another short story describing briefly how to invoke it, etc. I suppose I didn't say anything about how to read the resulting report, but in short, you can drill down into individual source files to see which lines are exercised by existing tests -- green = covered, red = uncovered. Now I'm wondering if OpenClover has a colorblind-friendly mode...)
Taking advantage of that, I see some untested behavior in parseString:
- unterminated plural constant (e.g. `$booleans[`)
- other escaped sequences (end-of-string, e.g. "\"", "\r", "\t", "\,", "\xABCD", "\uABCD", "\777") as well as malformed variants (invalid hex sequences, invalid octal)
- unterminated template substitutions
- comments
- nested brackets within a typed constant, e.g. $item[[glitch season reward name]])
(Just as some food for thought, to get you started down the rabbit hole that is coverage.)
Now, obviously I don't expect you to get Parser.java up to 100% absolute coverage, so use your judgment for which cases you're most worried about / which cases your parsing changes are most likely to have impacted.
(There's a notion of incremental code coverage as well, which is filtered down to the lines that you've added/modified. I'd like that to be no less than 80%, but preferably 90-100%. I don't see a great way of measuring that in OpenClover, though.)
Damn, that thing is THOROUGH...I spent yesterday working on integrating OpenClover, which I submitted this morning. (There's another short story describing briefly how to invoke it, etc. I suppose I didn't say anything about how to read the resulting report, but in short, you can drill down into individual source files to see which lines are exercised by existing tests -- green = covered, red = uncovered. Now I'm wondering if OpenClover has a colorblind-friendly mode...)
Here are some more tests in those lines.Taking advantage of that, I see some untested behavior in parseString:
- unterminated plural constant (e.g. `$booleans[`)
- other escaped sequences (end-of-string, e.g. "\"", "\r", "\t", "\,", "\xABCD", "\uABCD", "\777") as well as malformed variants (invalid hex sequences, invalid octal)
- unterminated template substitutions
- comments
- nested brackets within a typed constant, e.g. $item[[glitch season reward name]])
Some notes:
- Bad octal characters (the exception that reads "Octal character escape requires 3 digits") isn't tested. This is intentional. Currently, octal characters detection and parsing is improper, as the method requires 3 digits, and prints the same error message claiming that you needed 3 digits if something else was the issue.
Actual requirements for octal characters are:- If the first, *or* (the first && the second) digit(s) is/are 0, they are optional.
This "\1" is a valid equivalent for "\001" or "\01".
While this means that the error message is wrong ("Octal character escape requires 3 digits"), it would be understandable to require 3 digits for easier parsing, but this can very well be easily changed in the future, so manually making sure that this rule is always enforced would be inconvenient. - The 3rd and 2nd digits can only range between 0 and 7. The first digit (if you used 3 digits) can only range between 0 and 3.
While the parser does also make sure the supplied value meets those rules, it will still print the same error message as before if this rule isn't met (claiming that you didn't supply 3 digits). This means that trying to reach this section this way would be improper.
- If the first, *or* (the first && the second) digit(s) is/are 0, they are optional.
- Abruptly interrupted octal/hexadecimal/unicode characters (e.g. "\u1" or "\x") isn't tested.
This is because they currently result in an error (Parser doesn't check if the line is long enough before trying "line.substring( i, i + X )")
This is fixed on my side, but wasn't submitted on the Tokens patch as to not bloat it. - Escaped end of line/file in singular typed constants (i.e. "$int[\"). (Or any other escaped characters in singular typed constants)
Idem. On top of that, I plan to propose to allow escaped characters in singular typed constant, which would, at the same time, fix this issue. - Unterminated template substitutions.
As noted in the patch, that one was commented out because the expected error message is just about to change with the Tokens patch (though I did make sure that it's still passed on my end).
Attachments
Nice -- you're getting close to full coverage of parseString, modulo those things you called out. I think we can move on to other functions.
One thing that Clover notes that you're still missing is a single "/" (vs // for a comment). (Hooray, branch coverage!)
What's the value of allowing escapes in singular typed constants? The ability to type $item[\[glitch season reward name\]]?
Either way, this also looks good. r20824.
On to parseTypedConstant, since you've gotten a start there:
Recognition of plurals by trying to deduce singular form: ies -> y ($bounties[]), es ($classes[]), s ($skills[]), a -> um ($phyla[])
Unknown type (and not a recognized plural ending)
Still unknown type (after matching on known plural ending), e.g. $kolmafia (ends with "a"...)
Non-primitive type (perhaps something like... `record my_record{}; $my_record;`?)
No [ found
Trying to enumerate a type that cannot be explicitly enumerated ($ints[])
backslash escape (which it already has...?)
Further, I will note (as I'm sure you're well aware) that this simple ParserTest only checks for cases where you throw an error, but not for actual differences in parse result (you had to check the actual output of the template substitution via CustomScriptTest). We could ostensibly extend it to perform some match against the output of BasicScope.print(), but that seems... less pleasant to write tests against.
ParserTest's utility is really in checking for parse errors and making sure those don't cause NPEs or other exceptions, so I think it's worth calling out its limitations.
One thing that Clover notes that you're still missing is a single "/" (vs // for a comment). (Hooray, branch coverage!)
What's the value of allowing escapes in singular typed constants? The ability to type $item[\[glitch season reward name\]]?
Either way, this also looks good. r20824.
On to parseTypedConstant, since you've gotten a start there:
Recognition of plurals by trying to deduce singular form: ies -> y ($bounties[]), es ($classes[]), s ($skills[]), a -> um ($phyla[])
Unknown type (and not a recognized plural ending)
Still unknown type (after matching on known plural ending), e.g. $kolmafia (ends with "a"...)
Non-primitive type (perhaps something like... `record my_record{}; $my_record;`?)
No [ found
Trying to enumerate a type that cannot be explicitly enumerated ($ints[])
backslash escape (which it already has...?)
Further, I will note (as I'm sure you're well aware) that this simple ParserTest only checks for cases where you throw an error, but not for actual differences in parse result (you had to check the actual output of the template substitution via CustomScriptTest). We could ostensibly extend it to perform some match against the output of BasicScope.print(), but that seems... less pleasant to write tests against.
ParserTest's utility is really in checking for parse errors and making sure those don't cause NPEs or other exceptions, so I think it's worth calling out its limitations.
Oh, this *will* need to be modified.Further, I will note (as I'm sure you're well aware) that this simple ParserTest only checks for cases where you throw an error, but not for actual differences in parse result (you had to check the actual output of the template substitution via CustomScriptTest). We could ostensibly extend it to perform some match against the output of BasicScope.print(), but that seems... less pleasant to write tests against.
ParserTest's utility is really in checking for parse errors and making sure those don't cause NPEs or other exceptions, so I think it's worth calling out its limitations.
One feature that I added with my language server feature is to *no longer have Parser.java throw errors*.
Instead, it accumulates warnings and error messages in a list, which is checked at the end, so I'll have to make sure to also update ParserTest to be compatible with this when (if) we get there.
This is skipped, because my patch introduces a change in the error message.Recognition of plurals by trying to deduce singular form: ies -> y ($bounties[]), es ($classes[]), s ($skills[]), a -> um ($phyla[])
Currently, if you type, for example, "$a[]", Parser will turn the "a" into "um", and will re-parse the type.
Then, when it fails, it will generate the error message by using the new/edited word ("um").
My patch makes it remember the text originally used.
So in short, with my patch, the error message for "$a[]" goes from
"Unknown type um ()"
to
"Unknown type a ()"
Understood on both fronts.
Again, at this point, I think it's worth focusing on the changes that your patch(es) introduce, and corner cases you're worried about. Coverage is a useful guide for "hey should I be testing this?" but it's certainly easy to write a test that runs through all the code but doesn't assert anything meaningful about it (which is when mutation testing comes into play...).
Again, at this point, I think it's worth focusing on the changes that your patch(es) introduce, and corner cases you're worried about. Coverage is a useful guide for "hey should I be testing this?" but it's certainly easy to write a test that runs through all the code but doesn't assert anything meaningful about it (which is when mutation testing comes into play...).
Here's the rest. That should be it (again, some of them are commented out because of error message conflict between the current version and the patch's)
btw...
wtf?
btw...
Code:
[junit] Clover estimates having saved around 6 hours on this optimized test run. The full test run takes approx. 6 hoursAttachments
I turned on Clover's "optimize tests" feature which basically just caches test results using some heuristic (I think it's something like "was the source/test file last modified more recently than the last test execution?"). I don't know how exactly it arrives at its estimates, but it's probably based on however long the cached executions took when they last ran.
In general, Clover behaves badly if you're mixing classes built without coverage, with classes built with coverage; from my limited testing, this bad behavior seems to be exacerbated (and cached) by this feature. But, on the flip side, if you don't run into this, then it does save a significant amount of time in running tests.
I extended the non-traditional plurals test to also include $phyla[] to exercise that last test case, but otherwise, seems fine to me. r20825.
In general, Clover behaves badly if you're mixing classes built without coverage, with classes built with coverage; from my limited testing, this bad behavior seems to be exacerbated (and cached) by this feature. But, on the flip side, if you don't run into this, then it does save a significant amount of time in running tests.
I extended the non-traditional plurals test to also include $phyla[] to exercise that last test case, but otherwise, seems fine to me. r20825.
Either way, if you want, I've taken an initial pass at the Line class:
I think you can see why I wanted to wait until I had some time to look at this properly -- I'm a picky reviewer.
Diff:
+ public final class Line
+ {
+ private final String content;
+ private final int lineNumber;
+ private final int offset;
+
+ private final Deque<Token> tokens = new LinkedList<>();
(I'm mildly upset that Stack isn't an interface implemented by Deque, as it
would convey your usage better here.)
+
+ private final Line previousLine;
+ /** Not made final to avoid a possible StackOverflowError. Do not modify. */
+ private Line nextLine = null;
+
+ private Line( final LineNumberReader commandStream )
+ {
+ this( commandStream, null );
+ }
+
+ private Line( final LineNumberReader commandStream, final Line previousLine )
+ {
+ this.previousLine = previousLine;
+ if ( previousLine != null )
+ {
+ previousLine.nextLine = this;
+ }
+
+ int offset = 0;
+ String line;
+
+ try
+ {
+ line = commandStream.readLine();
+ }
+ catch ( IOException e )
+ {
+ // This should not happen. Therefore, print
+ // a stack trace for debug purposes.
+
+ StaticEntity.printStackTrace( e );
+ line = null;
Might I suggest initializing this.content / this.lineNumber / this.offset here
and then returning? That way you don't have to keep track of "maybe we caught an
error condition". Guards are generally useful for helping to reduce nesting and
the amount of mental state needed.
https://en.wikipedia.org/wiki/Guard_(computer_science)
+ }
+
+ if ( line != null )
+ {
+ // If the line starts with a Unicode BOM, remove it.
This is slightly incorrect behavior, as it can trigger in the middle of a file,
where Unicode says it should be treated as a zero-width non-breaking space. But,
I see that's consistent with what we're doing today.
(Nothing needed here, just worth noting.)
+ if ( line.length() > 0 &&
+ line.charAt( 0 ) == Parser.BOM )
+ {
+ line = line.substring( 1 );
A wild string copy appeared! (Again, apparently in existng code. This doesn't
seem like something Java cares about.)
+ offset += 1;
+ }
+
+ // Remove whitespace at front and end
+ final String trimmed = line.trim();
+ final int ltrim = line.indexOf( trimmed );
This is more expensive than likely needed, but until it's a proven performance
issue, it's likely better to leave it as the more obvious solution.
Java's String.indexOf( String ) is mostly optimized for this situation, anyways (although, we
still need to read through the end of the line to make sure these strings are
identical).
The "better" (at least, more efficient) implementation might look something like...
if ( !trimmed.isEmpty() )
{
// Here, line.indexOf( trimmed ) == line.indexOf( trimmed.charAt( 0 ) )
offset += line.indexOf( trimmed.charAt( 0 ) );
}
+
+ if ( ltrim > 0 )
+ {
+ offset += ltrim;
+ }
+
+ line = trimmed;
+ }
+
+ this.content = line;
+
+ if ( line != null )
+ {
+ this.lineNumber = commandStream.getLineNumber();
+ this.offset = offset;
+ }
+ else
+ {
+ // We are the "end of file"
+ // (or there was an IOException when reading)
Instead of needing to think about both these cases, can we add an early return
from the catch block as requested above? Regardless, I'd recommend moving this
up after the try/catch statement, as the following:
if ( line == null )
{
this.lineNumber = this.previousLine != null ? this.previousLine.lineNumber : 0;
this.offset = this.previousLine != null ? this.previousLine.offset : 0;
this.content = null;
return;
}
Then, you can go through the rest of the constructor without worrying if line
might be null.
+ this.lineNumber = this.previousLine != null ? this.previousLine.lineNumber : 0;
+ this.offset = this.previousLine != null ? this.previousLine.offset : 0;
+ }
+ }
+
+ private String substring( final int beginIndex )
+ {
+ // subtract "offset" from beginIndex, since
+ // we already removed it
+ return this.content.substring( beginIndex - this.offset );
Is it okay for this function to be unchecked?I think you can see why I wanted to wait until I had some time to look at this properly -- I'm a picky reviewer.